
Google认可自动化的价值,并且由于Google特有的业务挑战,Google更倾向于自动化:Google的产品和服务是全球部署的,通常没有时间和其他组织一样手动维护系统。尽管Google在思想上倾向于尽可能使用机器管理机器,但是实际情况需要一定的变通。将每个系统的每个组件都自动化是不合适的,同时不是所有人都有能力或者倾向于在一个特定的时间开发自动化系统。
的自动化广泛使用,Puppet是一个开源 软件配置管理工具。它可以在许多类Unix系统上运行,也可以在Microsoft Windows上运行,并包含自己的声明性语言来描述系统配置。
Chef,Chef是一家公司,也是用Ruby和Erlang编写的配置管理工具的名称。它使用纯Ruby,特定于域的语言(DSL)来编写系统配置“食谱”。Chef用于简化配置和维护公司服务器的任务,并可与基于云的平台集成,如Internap,Amazon EC2,Google Cloud Platform,Oracle Cloud,OpenStack,SoftLayer,Microsoft Azure和Rackspace自动配置和配置新机器。Chef包含适用于小型和大型系统的解决方案,具有各自范围的功能和定价。
cfengine,CFEngine是一个开源 配置管理系统,其主要功能是提供大规模计算机系统的自动配置和维护,包括服务器,台式机,消费和工业设备,嵌入式网络设备,移动智能手机和平板电脑的统一管理。
Perl提供POSIX级别的接口,在系统API层提供了一个基本上是无限的扩展范围,而Chef和Puppet则提供了一些“开箱即用”的抽象层,通过对这些抽象层的操作可以直接操作服务或者其他高级对象。SRE在自动化领域有一系列设计哲学和产品,它们中的一些类似于一种不会特别详细地对高层次实体建模的通用部署工具,另外一些则类似于在非常抽象的层次上描述服务部署的语言。

GoogleSRE的自动化历程经历了以上几个阶段:
第一阶段是完全依赖手动操作的无自动化阶段,左上角图中,就是采用shell脚本通过ssh来应对繁琐的包分发和服务初始化问题。
第二阶段是使用外部维护的特定系统的自动化脚本来进行操作,例如左下角CISCOFabric Manager,这是由CISCO开发的网络管理工具。
第三阶段是特定的系统自动化逐步演进为通用的系统自动化,例如右下角SPLUNK就可以收集大多数设备、系统的日志,通过日志来进行运维管理。
第四阶段是用内部维护的自动化系统替代外部维护的自动化系统。
第五阶段最终演化为纳入运维平台无需人工触发的自动化系统。
往期学友们问题合集:
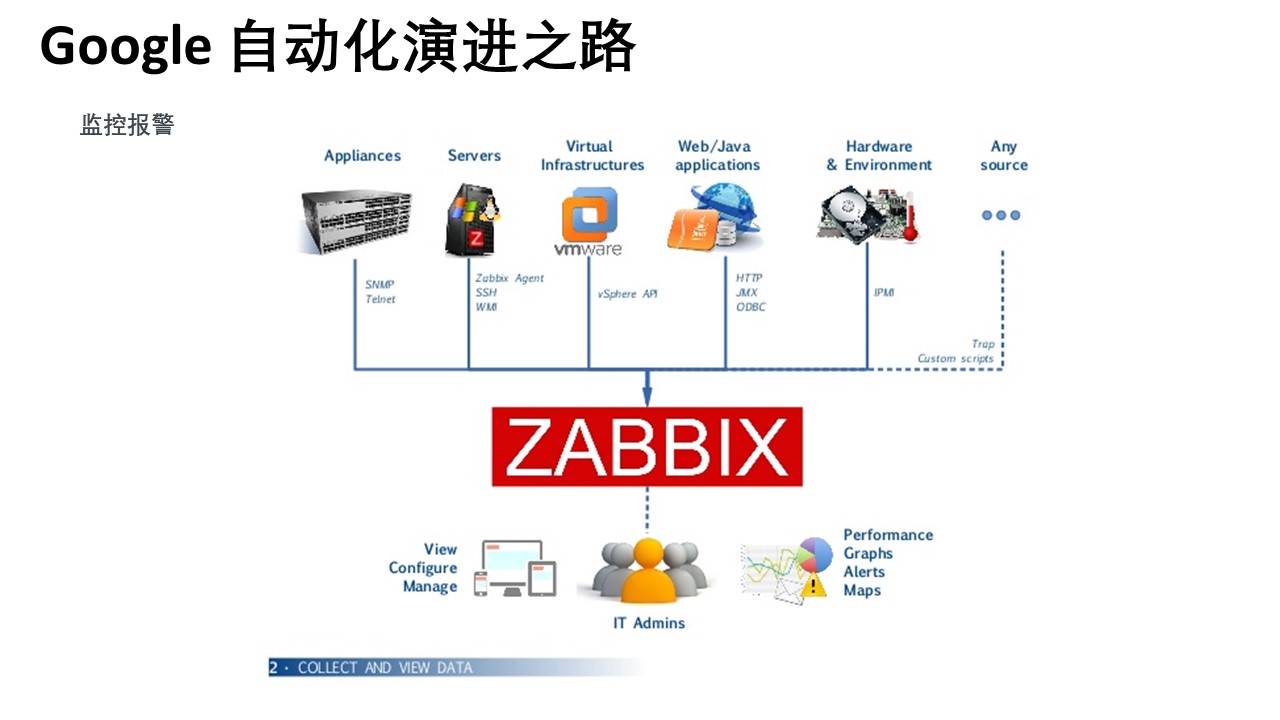
Q1:Zabbix用的越来越少了,Promitheus会替代吗?告警用什么最合适?
这个要根据你用的系统和应用而言,这个是一些开源软件监控、告警、时间序列的组合,有自身的优点也有一定的缺点。会不会被替代是要看历史和大家应用的情况。告警用什么最合适也是根据系统和应用,没有最佳的一个方案。使用有商用的或是开源的,是根据自身的状况选择。
Q2:产品开发作为过程有没有必要使用apm产品?
Apm主要是应用监控,应用监控我们要在开发过程中考虑到,比方说上线变更之前,系统在生产运行的过程中可能会出现哪些问题,出现问题如何应急进行一些相应的操作。那如何发现这些问题,那一部分我们可以用apm来实现,这个可以和我们测试的时候进行结合,比如说我们目前企业已有的amp产品和新开发的应用能不能有效的结合起来。只要能有效的结合起来帮助业务,那我们在开发和测试的过程中还是有必要纳入进来的。
Q3:对类borg的k8s怎么看?
各有千秋,有那么多的产品能够生存下来肯定是有各自的一些优点。在用到不同的系统发生的事件或者处理情况都是不一样的。
Q4:私有云没有精力自己做监控,有什么开源可以直接上?
其实这个要看公司的资源,如果有人力和财务上的支持这块应该就能做起来。私有云看你怎么建了,像你把它的硬件环境作为我们的IDC或者说我们从云那边租一块它的环境,我们把操作系统、数据库、应用自己搭建。开源工具一般不会直接上,需要做一些相应的配置,定时、监控的方式,针对操作系统、网络、数据库这块相对容易有些公共的,但是应用部分肯定要结合开发的人员做配置,应用在运行的过程中会有哪些问题,如何用开源的工具监控它。用开源的工具去监控应用还是有些缺陷的,它只能把常规的一些问题发现,自己应用里面特有的状态是无法发现的,这就需要开发人员写一个应用状态的解测工具,这样才能实现私有云方面的监控,开源的只能保证通用的这些。




